SPORTS DATA ANALYZING
I always enjoyed the idea of counting cards to sway the advantage to the player instead of the house in games like blackjack. Blackjack was one of my first projects in python.
I was a big fan of basketball at the time and was looking at side hustles to try to make some extra cash. I thought about how you could count blackjack and thought why not try to predict sports games. How hard could it be?
The goal here was to predict NBA games at a reasonable rate. A rate that would allow me to make money if possible by betting on games where I saw a discrepancy between the bookies predictions and my own code. I would only bet against teams that were the underdog as well. Something I had learned from a betting on baseball book I read earlier in the year.
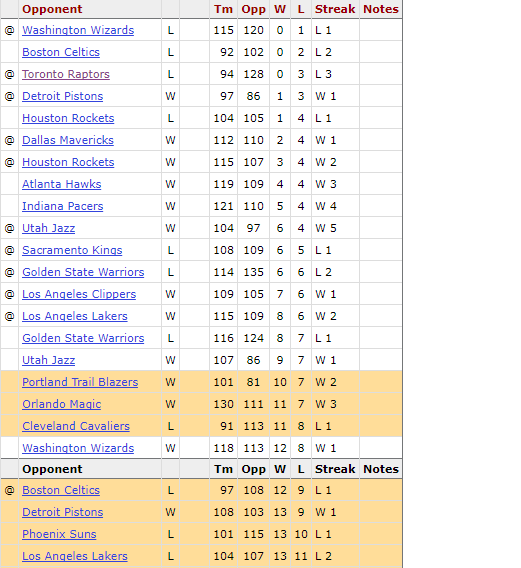
I first started by finding the schedule of each team of the year before. I would later compare my simulations predictions against this data to find how accurate it would become.
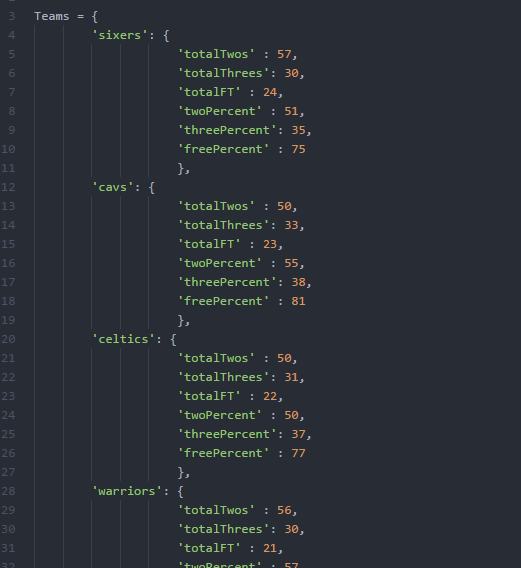
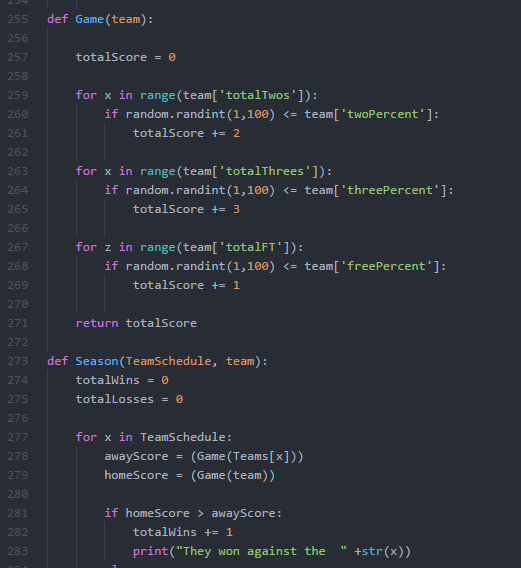
I went for a very simple logic which was that I would add up average point systems scored in a season and apply that across every game. There are several ways to score. 2 pointers, 3 pointers, and free-throws. I added up the average number of each of these taken per game as well as the percentages made for each of them. Then they were thrown into a randomizer.
The simulations ended up running with roughly a 70% accuracy. Certain teams were much more accurate than others. Teams that had a more average amount of shots of each type tended to by far more predictable than teams that were more than one standard deviation away from the average amount of shots taken. I never ended up using this to bet on games but instead used it as a stepping stone to learn more about how to use data to predict outcomes.